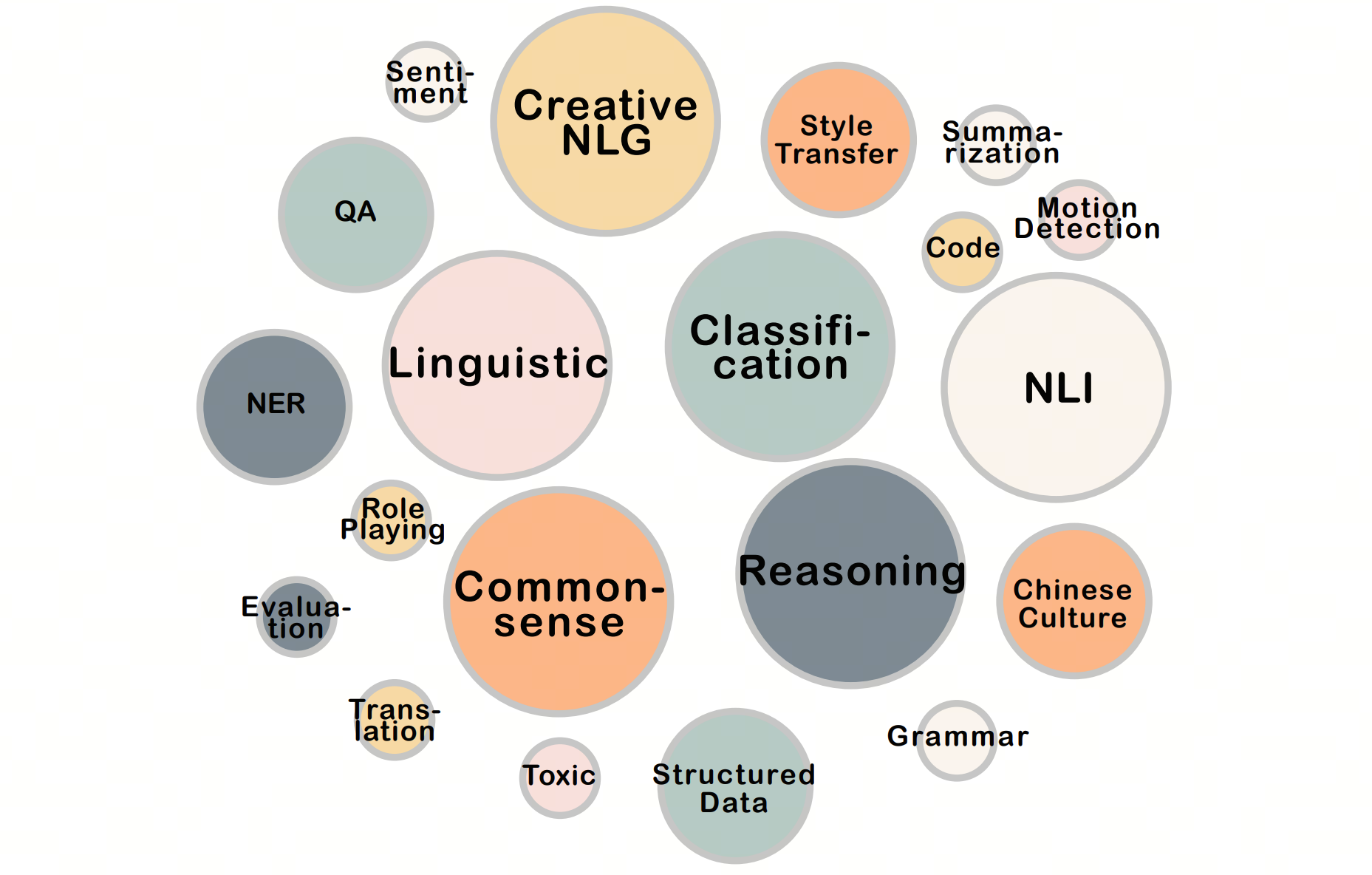
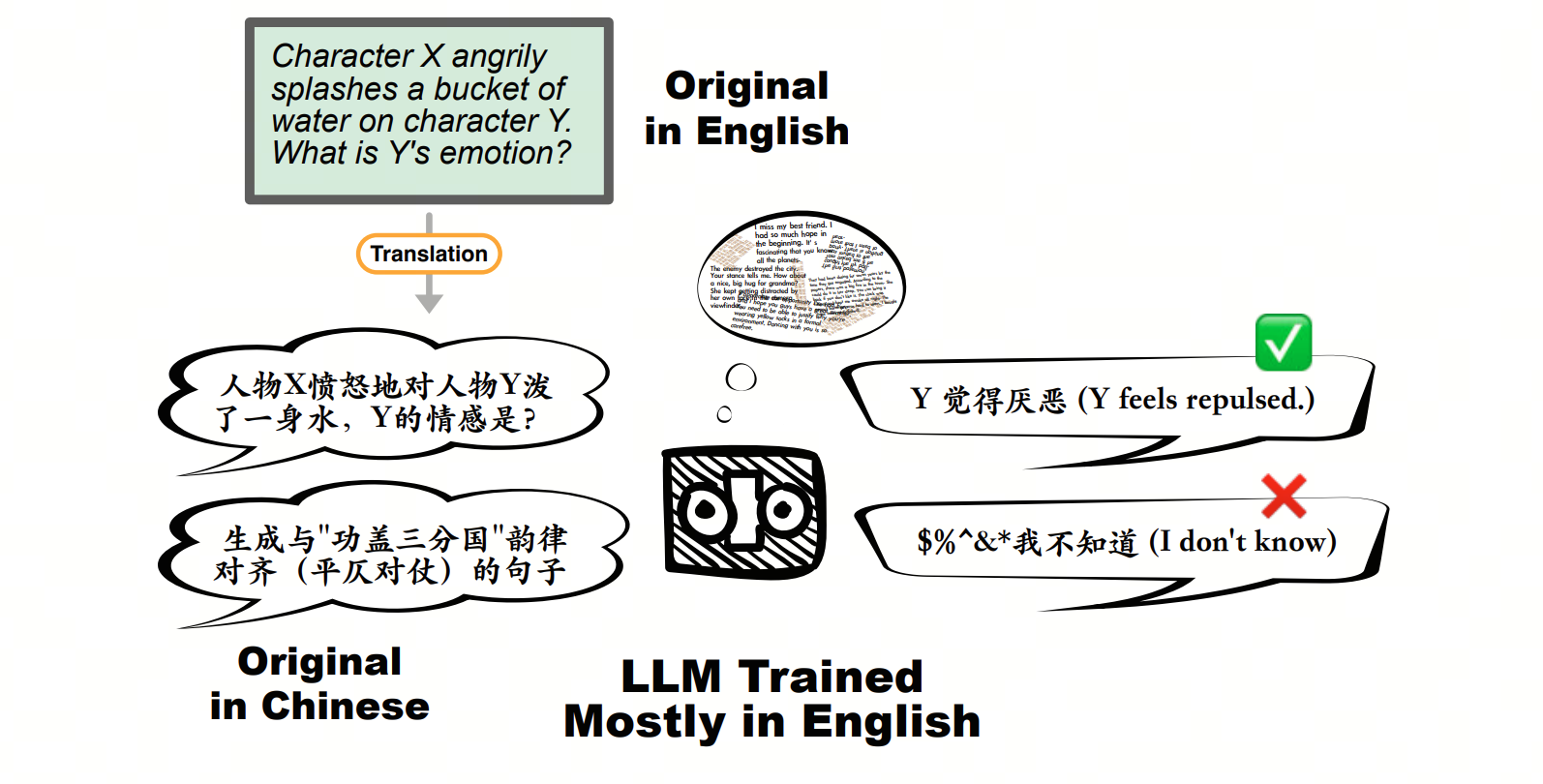
As the CIF-Bench aims to provide a comprehensive evaluation of the LLM instruction-following capability, we argue that the metrics should be designed case by case in task granularity to evaluate the open-ended textual outputs, rather than simply reformatting all tasks into choice questions and using the conditional probability to approximate the models' predictions.
After a thorough review of the task instructions, we categorize the output requirements into the four following types and design corresponding task-level metrics. Multi-class Classification: We use accuracy as the metric if the task requires the model to predict one label from 2 or more classes in the output. Multi-label Classification: We use F1 score as the metric if the task requires the model to predict one label from 2 or more classes in the output. Creative Generation: Regarding the tasks that have no absolute criteria of the standard answer, we require a model-based evaluator to provide information regarding a given output, including creativity, fluency, the level of instruction-following, and the confidence of the evaluator. Semantic Similarity: For the remaining tasks that can be evaluated by the semantic similarity between the golden reference and model output, we use a pre-trained language. All scores used in CIF-Bench either naturally range from 0 to 1, or are normalized to the same range.
One core dilemma in evaluating the open-ended instruction-following capabilities of LLMs is that model predictions are hard to verify even with reference answers. For instance, it is intractable to handcraft regex rules to extract the predictions from LLMs for the extensive number of tasks, since the answers could be expressed in various formats, or drowned in redundant contexts like reasoning progress. Inspired by G-Eval, we leverage OpenAI's GPT-4 as a relatively reliable evaluator for multi-class classification, multi-label classification, and creative generation tasks, to overcome such issues. The GPT-4 evaluator is prompted to assess the outputs according to the given task instruction and the input-output reference. For the answers that can be evaluated with semantic similarity, we use a lightweight multilingual encoder, BLEURT, to measure the relevance between the reference and LLM output.
Given a set of task instructions , we denote the performance score of model on task as: , where refers to the set of data samples for task . In the case of the public split, the instruction set is reduced to one single element. In we take the average of task-level scores as the indicator of overall performance for a model .Leaderboard
| Model Name | Overall | Chinese Culture | Classification | Code | Commonsense | Creative NLG | Evaluation | Grammar | Linguistic | Motion Detection | NER | NLI | QA | Reasoning | Role Playing | Sentiment | Structured Data | Style Transfer | Summarization | Toxic | Translation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 0.529 | 0.520 | 0.674 | 0.333 | 0.641 | 0.497 | 0.686 | 0.542 | 0.528 | 0.578 | 0.563 | 0.632 | 0.569 | 0.515 | 0.752 | 0.624 | 0.459 | 0.462 | 0.332 | 0.441 | 0.273 |
| Qwen-72B-Chat | 0.519 | 0.486 | 0.630 | 0.296 | 0.634 | 0.508 | 0.634 | 0.458 | 0.520 | 0.494 | 0.550 | 0.626 | 0.565 | 0.528 | 0.762 | 0.613 | 0.496 | 0.459 | 0.282 | 0.608 | 0.271 |
| Yi-34B-Chat | 0.512 | 0.483 | 0.606 | 0.347 | 0.623 | 0.497 | 0.598 | 0.480 | 0.490 | 0.575 | 0.525 | 0.619 | 0.554 | 0.494 | 0.757 | 0.580 | 0.472 | 0.439 | 0.346 | 0.514 | 0.259 |
| Qwen-14B-Chat | 0.500 | 0.481 | 0.582 | 0.307 | 0.614 | 0.494 | 0.645 | 0.428 | 0.475 | 0.496 | 0.513 | 0.616 | 0.548 | 0.507 | 0.764 | 0.583 | 0.469 | 0.453 | 0.283 | 0.575 | 0.262 |
| Deepseek-Llm-67B-Chat | 0.471 | 0.467 | 0.571 | 0.259 | 0.577 | 0.486 | 0.549 | 0.442 | 0.476 | 0.475 | 0.509 | 0.566 | 0.496 | 0.439 | 0.711 | 0.546 | 0.409 | 0.436 | 0.262 | 0.570 | 0.235 |
| Baichuan-13B-Chat | 0.450 | 0.408 | 0.491 | 0.286 | 0.552 | 0.439 | 0.670 | 0.417 | 0.422 | 0.482 | 0.486 | 0.565 | 0.505 | 0.377 | 0.704 | 0.552 | 0.387 | 0.402 | 0.350 | 0.431 | 0.304 |
| Chatglm3-6B | 0.436 | 0.381 | 0.439 | 0.330 | 0.541 | 0.452 | 0.577 | 0.310 | 0.358 | 0.436 | 0.453 | 0.544 | 0.503 | 0.414 | 0.762 | 0.560 | 0.446 | 0.402 | 0.321 | 0.391 | 0.270 |
| Yi-6B-Chat | 0.417 | 0.402 | 0.454 | 0.313 | 0.523 | 0.425 | 0.506 | 0.383 | 0.383 | 0.487 | 0.396 | 0.523 | 0.457 | 0.369 | 0.754 | 0.482 | 0.401 | 0.380 | 0.310 | 0.455 | 0.227 |
| Baichuan2-7B-Chat | 0.412 | 0.437 | 0.647 | 0.160 | 0.520 | 0.402 | 0.580 | 0.511 | 0.444 | 0.455 | 0.407 | 0.489 | 0.395 | 0.406 | 0.670 | 0.517 | 0.342 | 0.298 | 0.101 | 0.463 | 0.138 |
| Chatglm2-6B | 0.352 | 0.278 | 0.469 | 0.346 | 0.403 | 0.424 | 0.535 | 0.274 | 0.397 | 0.406 | 0.240 | 0.397 | 0.352 | 0.326 | 0.714 | 0.438 | 0.298 | 0.313 | 0.320 | 0.461 | 0.190 |
| Chatglm-6B-Sft | 0.349 | 0.265 | 0.454 | 0.365 | 0.385 | 0.462 | 0.554 | 0.296 | 0.379 | 0.427 | 0.232 | 0.380 | 0.321 | 0.292 | 0.718 | 0.415 | 0.296 | 0.333 | 0.351 | 0.441 | 0.190 |
| Chinese-Llama2-Linly-13B | 0.344 | 0.250 | 0.462 | 0.311 | 0.399 | 0.429 | 0.557 | 0.273 | 0.358 | 0.385 | 0.268 | 0.390 | 0.330 | 0.313 | 0.653 | 0.433 | 0.279 | 0.332 | 0.292 | 0.457 | 0.181 |
| Gpt-3.5-Turbo-Sft | 0.343 | 0.269 | 0.427 | 0.298 | 0.389 | 0.395 | 0.575 | 0.325 | 0.365 | 0.389 | 0.226 | 0.382 | 0.394 | 0.345 | 0.710 | 0.433 | 0.324 | 0.266 | 0.290 | 0.397 | 0.225 |
| Chinese-Alpaca-2-13B | 0.341 | 0.242 | 0.421 | 0.356 | 0.382 | 0.442 | 0.602 | 0.256 | 0.363 | 0.430 | 0.210 | 0.376 | 0.334 | 0.317 | 0.714 | 0.459 | 0.299 | 0.316 | 0.308 | 0.452 | 0.200 |
| Chinese-Alpaca-13B | 0.334 | 0.250 | 0.399 | 0.348 | 0.364 | 0.435 | 0.616 | 0.275 | 0.349 | 0.421 | 0.223 | 0.370 | 0.309 | 0.319 | 0.724 | 0.426 | 0.285 | 0.307 | 0.298 | 0.445 | 0.181 |
| Chinese-Alpaca-7B | 0.334 | 0.216 | 0.412 | 0.378 | 0.381 | 0.425 | 0.576 | 0.265 | 0.359 | 0.393 | 0.243 | 0.383 | 0.326 | 0.295 | 0.710 | 0.409 | 0.301 | 0.327 | 0.325 | 0.405 | 0.186 |
| Chinese-Llama2-Linly-7B | 0.333 | 0.218 | 0.451 | 0.330 | 0.396 | 0.427 | 0.583 | 0.248 | 0.350 | 0.410 | 0.231 | 0.367 | 0.345 | 0.276 | 0.698 | 0.433 | 0.259 | 0.315 | 0.310 | 0.469 | 0.168 |
| Tigerbot-13B-Chat | 0.331 | 0.205 | 0.397 | 0.309 | 0.385 | 0.420 | 0.614 | 0.310 | 0.379 | 0.341 | 0.276 | 0.363 | 0.329 | 0.301 | 0.694 | 0.419 | 0.280 | 0.310 | 0.283 | 0.393 | 0.186 |
| Telechat-7B | 0.329 | 0.267 | 0.338 | 0.321 | 0.420 | 0.404 | 0.420 | 0.272 | 0.265 | 0.327 | 0.320 | 0.388 | 0.355 | 0.244 | 0.672 | 0.344 | 0.334 | 0.335 | 0.299 | 0.364 | 0.184 |
| Ziya-Llama-13B | 0.329 | 0.196 | 0.402 | 0.324 | 0.341 | 0.428 | 0.616 | 0.312 | 0.349 | 0.400 | 0.228 | 0.351 | 0.279 | 0.313 | 0.721 | 0.468 | 0.311 | 0.291 | 0.278 | 0.431 | 0.175 |
| Chinese-Alpaca-33B | 0.326 | 0.234 | 0.370 | 0.372 | 0.364 | 0.429 | 0.614 | 0.246 | 0.318 | 0.377 | 0.221 | 0.368 | 0.300 | 0.314 | 0.713 | 0.428 | 0.288 | 0.303 | 0.295 | 0.401 | 0.199 |
| Tigerbot-7B-Chat | 0.325 | 0.218 | 0.395 | 0.306 | 0.370 | 0.413 | 0.631 | 0.294 | 0.370 | 0.368 | 0.215 | 0.355 | 0.313 | 0.292 | 0.713 | 0.415 | 0.283 | 0.315 | 0.290 | 0.389 | 0.171 |
| Chinese-Alpaca-2-7B | 0.323 | 0.215 | 0.374 | 0.335 | 0.366 | 0.415 | 0.546 | 0.257 | 0.326 | 0.395 | 0.215 | 0.375 | 0.318 | 0.289 | 0.698 | 0.417 | 0.285 | 0.303 | 0.312 | 0.439 | 0.193 |
| Aquilachat-7B | 0.309 | 0.162 | 0.234 | 0.291 | 0.320 | 0.437 | 0.344 | 0.135 | 0.266 | 0.309 | 0.287 | 0.337 | 0.342 | 0.236 | 0.609 | 0.255 | 0.249 | 0.400 | 0.527 | 0.430 | 0.306 |
| Moss-Moon-003-Sft | 0.302 | 0.214 | 0.405 | 0.274 | 0.347 | 0.380 | 0.448 | 0.305 | 0.341 | 0.378 | 0.232 | 0.317 | 0.321 | 0.267 | 0.694 | 0.375 | 0.251 | 0.259 | 0.288 | 0.424 | 0.152 |
| Qwen-7B-Chat | 0.301 | 0.211 | 0.410 | 0.289 | 0.349 | 0.391 | 0.531 | 0.219 | 0.387 | 0.404 | 0.208 | 0.325 | 0.297 | 0.278 | 0.681 | 0.419 | 0.266 | 0.251 | 0.248 | 0.371 | 0.157 |
| Belle-13B-Sft | 0.264 | 0.198 | 0.307 | 0.285 | 0.316 | 0.349 | 0.409 | 0.237 | 0.305 | 0.222 | 0.177 | 0.317 | 0.284 | 0.242 | 0.631 | 0.299 | 0.244 | 0.222 | 0.234 | 0.296 | 0.133 |
| Cpm-Bee-10B | 0.244 | 0.234 | 0.377 | 0.024 | 0.278 | 0.311 | 0.255 | 0.302 | 0.278 | 0.327 | 0.148 | 0.286 | 0.224 | 0.147 | 0.603 | 0.277 | 0.117 | 0.263 | 0.220 | 0.352 | 0.125 |